
There’s no good way of identifying the most complex usage-based pricing models in existence. There are almost 10,000 SaaS and cloud providers worldwide. Some publish pricing on their websites, while others only share the specifics with customers or prospects during a sales cycle. Most use a straightforward subscription model where the customer pays a fixed fee per user per month for access to the service. However, the more interesting models are the 1% that use consumption-based pricing. This increasingly popular option enables cloud providers to expand the value metric beyond simple “per user” to an infinite number of alternative metrics.

There is no ranking of the most creative and complex pricing models, but if there were a top 10 list, most would have Alibaba’s MaxCompute on it. At first glance, the pricing does not look very complex – simple multiplication of three different variables. However, there is additional hidden complexity in the steps required to determine each variable, particularly the second one – “SQL complexity.” We’ll perform a teardown pricing analysis below to highlight the complexity.

“Complexity” is not necessarily a Bad Thing in Usage-Based Pricing
Historically, the goal of most pricing strategies was to balance simplicity with growth potential. Cloud providers wanted the pricing to be simple enough that a customer could understand it but accurate enough to enable them to recover costs and grow revenue in alignment with actual usage.
However, as customers grow more familiar with pricing models, many are beginning to prioritize precision and fair value over simplicity. Customers would rather be charged $9250 per month with a complex pricing model than $10,000 per month using a simple approach.
Complex Usage-Based Pricing Teardown
MaxCompute service is a data warehouse that runs on Alibaba’s cloud computing platform. It analyzes large-scale data sets such as website traffic logs, e-commerce purchases, and end-user activity. Because MaxCompute deals with very high volumes of data, there is a risk that the service could become cost-prohibitive if simple pricing were used. Therefore, a very granular level of precision is needed to align the price with the value received by the customer and the cost incurred by the vendor.
Fees are charged for each SQL job submitted to the data warehouse using a sophisticated version of the quantity x price model.
In simple terms the formula is:
Fee = volume of data x complexity of query x unit price
- Quantity = volume of data
- Rate Multiplier = complexity of query
- Price = unit price
Let’s review each of the three parts of the calculation in further depth:
Quantity
Part One
The quantity in the formula is a volume metric – GB of data processed by the SQL query. However, Alibaba adjusted the volume to exclude data rows, and columns unimportant to the query and better align the price charged with the value received.

For example, suppose we wrote a SQL query to extract the top 5 all-time home run leaders in Major League Baseball. The database table might look something like the one below.
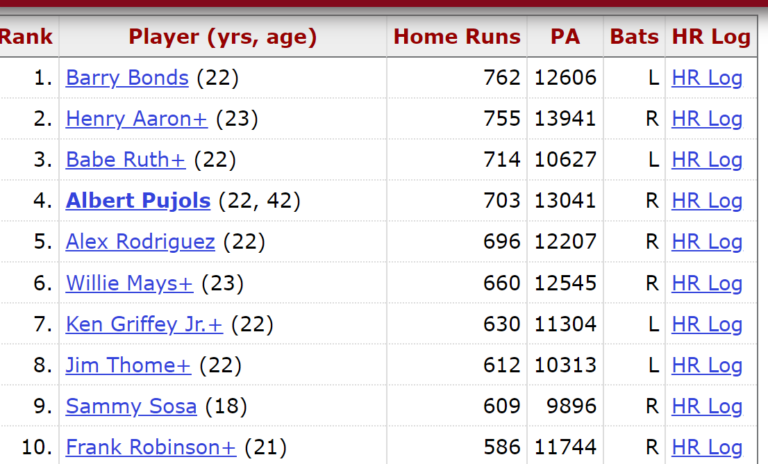
Source: Baseball-Reference.com
However, we only want to grab the player name, rank, and home run total for our query. In other words, we only need three columns of data (rank, player, home runs) from 5 out of 10 rows. Therefore, in computing the price, Alibaba would exclude the two extra columns (plate appearances and batting arm) from the calculation and the rows starting with Willie Mays (#6-10).
MaxCompute is designed for large-scale data sets in the petabyte and exabyte range. For example, one query might have to search through a table with trillions of rows might need to be searched to select only a few thousand matching the criteria. The cost of the service would quickly become prohibitively expensive if the customer were charged for a few trillion rows of data each time the table was queried.
Rate Multiplier
Part Two
The most interesting part of the pricing model is the rate multiplier that is applied based upon the complexity of the SQL query. Alibaba has arrived at a specialized formula that attempts to fairly charge the customer a different price based upon the performance load the SQL job puts on its computing resources. The idea is that more complex SQL queries that use more computing power and memory are charged more than more straightforward jobs.

SQL Complexity is determined in a twtwo-steprocess
1) Determining the number of SQL keywords
2) Assigning a complexity value based on the number of SQL keywords (step #1) using a predefined table of ranges
Part 1 – SQL Keywords
SQL Keywords are arrived at in seven steps:
a) Count of the number of joins, group by, order by, and distinct clauses as well as window functions (count, sum, max, min) in the SQL query
b) Sum the total of each type of clause from step a
c) Count the number of inserts, delete, and update statements
d) Determine the maximum out of the count insert, delete, and update (step c)
e) Subtract one from the maximum determined in step d
f) Compare the result of step e to 1
g) The “SQL keyword count” is the higher of the two values or one if they are equal
Part 2 – Complexity Value
Now a complexity value needs to be assigned to the SQL query. Next, a rate multiplier is set based upon the SQL keyword count using the following table:
Price
Part Three
The unit price is the most straightforward part of the calculation. A flat/linear, single rate of $0.0438 per GB is offered.

Many cloud computing platforms provide discount schedules for volume-based pricing models. The customer pays a lower per-unit price as their consumption grows. The goal is incentivizing the customer to push more volume through the system. For example, the customer might only pay $0.0300 per GB for volumes over 1TB, $0.0200 per GB over 5TB, etc. Instead, MaxCompute customers can obtain a discount by committing to a subscription.








